 |
presented at: 32nd Hawaii International Conference on System Sciences (HICSS-32),
January 5-8, 1999, Island of Maui, Hawaii, USA.
Thomas Gschwind,
Manfred Hauswirth
{tom,
M.Hauswirth}@infosys.tuwien.ac.at
Distributed Systems Group
Technische Universität Wien
Usenet News [13] offers a world-wide discussion forum, which is divided into hierarchical newsgroups dedicated to defined topics, e.g., the comp hierarchy deals with computer related topics and the specific newsgroup comp.lang.java focuses on the Java programming language.
Users can access Usenet News, commonly denoted as News, via a news reader (client) which provides the user interface and manages the interaction with the news server. Users subscribe to a set of newsgroups based on their interests. After selecting a specific newsgroup, contributions (articles, postings) can be read by the user. If it is allowed by the news server, the user may submit replies to articles or post new ones. The News infrastructure then takes care of the world-wide distribution.
For focused discussions inside a newsgroup, postings can refer to each other by using article identifiers provided by the News system. News readers use these relations for convenient presentation of related articles (threading). Articles can also be posted to a set of newsgroups (cross-posting).
The provision of this blackboard functionality on a world-wide scale has made News a successful system that steadily grows in the number of newsgroups (currently over 55000 groups [15]) and users. At the infrastructure level this implies growing amounts of data that need to be distributed to an increasing number of computers. This growth steadily pushes the existing News infrastructure to its limits [19], [5].
Though flexible and scalable, News' underlying infrastructure may soon face scalability problems with coming requirements. In this paper we analyze the scalability problems of the current News system and present several approaches that can remedy these problems, while still providing continuous operation. The paper is structured as follows.
In Section 2 we start with a description of the existing News infrastructure which is then analyzed in Section 3 with focus on scalability issues. Based on this analysis we present possible solution strategies in Section 4 with the most promising solution using an access infrastructure of cache servers.
Section 5 presents the requirements for a cache server for News and gives a description of our NEWSCACHE implementation.
Section 6 gives statistical information that show how News can benefit from caching and discusses inter-operability with exiting software. Related work is considered in Section 7 and we draw our conclusions in Section 8.
To motivate the need for improvements and as a basis for the analysis in Section 3, this section presents the current News infrastructure.
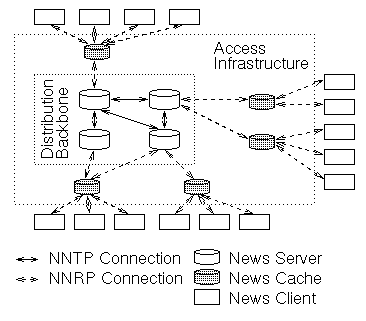
Figure 1 shows a simplified News network. Current News software falls into two classes: news readers (clients in Figure 1) and news servers. News readers handle interactions with the user as described above (user interface, reading and posting of articles). The Network News Reader Protocol1 (NNRP) is used for the interaction of news readers with the News distribution infrastructure. Each news reader communicates with exactly one news server.
The world-wide set of cooperating news servers makes up the distribution infrastructure of the News system. The Network News Transfer Protocol [12] (NNTP) is used to propagate articles among news servers. News servers receive articles from their clients and other news servers. Propagation of articles is commonly referred to as news feeding. Each news server defines which newsgroups it wants to hold, i.e., provide to its clients, and has a statically configured set of servers that constitute its news feed.
An article posted by a client is transferred via NNRP to its dedicated news server which is the client's access point to the News infrastructure. Each news server then keeps a copy of this article and propagates it to its neighboring news servers. This propagation finally results in a copy of each article on each news server in the infrastructure. Since no restriction exists on the topology and distribution paths of the News system, servers may receive an article multiple times. Hence, each article carries a globally unique identifier that allows news servers to identify duplicates. Causal ordering of articles, however, is not maintained by this distribution semantics: the different distribution paths of articles may cause that a reply reaches a news server before the article it refers to.
The data each news server holds is composed of several databases: article database, history database, and active database. The organization of these databases is simple. Usually the article database maps newsgroups and articles to the file system (C-News [6], INN [18], NNTP reference implementation). Each newsgroup is mapped to a directory with each article in a separate file. E.g., article 162 in comp.lang.java is stored as comp/lang/java/162. The history database records the article IDs and some administrative data of recently received articles in a history file, each line holding an entry for one article. The main purpose of the history database is the identification of duplicate articles. The active database also consists of a single file that lists the newsgroups available on a news server. Each newsgroup is represented by a one line record holding the range of currently active article numbers and the moderation status of the group. Additionally, most servers keep an overview database [4] which is one of the few improvements that have been applied to the original News standard [12]: to allow news clients to quickly display a content listing of a newsgroup the overview database holds a short summary for each article (date, subject, author, etc.).
The existing News infrastructure has some severe drawbacks that have become obvious after being in operation for several years. These drawbacks are mainly related to scalability with respect to the increased amount of data that needs to be transferred by the News infrastructure. In the following we describe the problems that have motivated our approach.
An enormous redundancy is caused by copying each article of a newsgroup to all the news servers holding this newsgroup. This is a problem in the current infrastructure since a high percentage of newsgroups and articles will not be read by anyone, so distribution would not have been necessary [14]. Statistics of news.tuwien.ac.at show that about 66% of all newsgroups are not read [15].
News' distribution semantics stems from UUCP [16] which originally was used for article distribution. UUCP is batch-oriented and does not support on-demand connections like HTTP.
As described in [15] and [5] a typical news feed requires 2.5 GB/day. In terms of network bandwidth the permanently needed bandwidth to transfer the current amount of data is approximately 400 Kbit/s. This means 27% of the bandwidth of a T1 link (1.5 Mbit/s), which is the typical Internet link for many sites, is dedicated to the news service.
Another problem is the I/O load of the news server. On our university's news server, news clients retrieve over 2.5 GB of article data every day, excluding requests for active and overview records. This means that news clients retrieve more articles than are fed to the news server (the same article can be requested by different clients). By mapping this number onto the I/O load caused by the news feed and the clients, we can estimate that clients are responsible for over 50% of the I/O load on the news server. Thus, a higher degree of scalability can be achieved by separating communication with clients from server communication.
A backlog in the news feed may occur if either the above minimum bandwidth requirement is not met, the news server is not operable for some time, or no Internet connectivity is available at all. If a backlog cannot be recovered, the quality of the news service has to be lowered either by decreasing the number of available newsgroups or by expiring articles earlier.
News' copy semantics also implies high disk space requirements, mainly caused by the filesystem-oriented organization of the article database: each article is stored in a separate file. Thus, considerable amounts of disk space--up to over 100% of the real data volume--are wasted [19].
Currently scalability problems are mainly managed by inflexible administrative measures. The approach presented in [5] suggests to replace one news server by a set of cooperating news servers where each news server holds part of the article spool. One dedicated news server is responsible for news distribution and the other servers handle client requests. This approach increases hardware expenses by approximately 100%, adds administrative overhead, and only provides a workaround for the problem. Our solution in contrast reduces both hardware requirements and administrative effort.
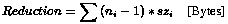
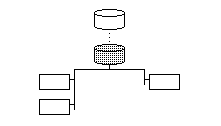 |
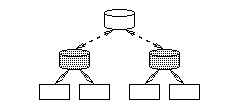 |
| (a) Slow link | (b) Load reduction |
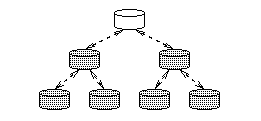 |
 |
| (c) Cascading (hierarchical caching) |
| compatibility | bandwidth req. | I/O load | hardware req. | |
|---|---|---|---|---|
| central | clients | higher | higher | higher |
| cache | clients and servers | lower at access infrastructure | lower at access infrastructure | lower |
| multicast | modified clients and servers | lower | higher | higher |
| compression | modified clients | lower | equal | lower |
| lightweight | proxy necessary | lower | lower | lower |
| backbone | clients and servers | equal | lower (no clients) | lower (fewer nodes) |
In this section we present the requirements for a cache server (based on our NEWSCACHE implementation). A detailed description of NEWSCACHE's prototype implementation can be found in [10].
To be an adequate solution, the cache server has to meet two main requirements:
The cache server has to issue control messages to ensure that the cached data are accurate. Each article carries a per newsgroup article identifier. The article corresponding to an article identifier must not be changed and its identifier may never be reused. Thus, a cached article will remain valid forever and no cache consistency verification is necessary.
In addition to the article identifier, each article has a per newsgroup article number. The lowest and highest article numbers in a newsgroup are denoted low and high watermarks. Whenever a new article arrives on the news server, the news server increases the high watermark and uses this value for the new article's per newsgroup number. This allows clients to detect new articles simply by requesting the low and high watermark (using the group command).
Since no callback functionality is included in the news server, the news reading client has to poll at regular intervals whether new articles have been added. This means that the news cache has to check for new articles whenever a client requests a newsgroup even if another client has requested the same newsgroup just a moment before. If we apply a more relaxed policy for cache accuracy, we can further reduce the load of the news server: we assume that the information, we have retrieved from the news server will not change within a certain time interval t.
The result of a relaxed caching accuracy is that new articles will be delivered to the cache server's clients with an average delay of t/2. If the news cache should provide new articles immediately, the timeout must be set to zero. This might be interesting for newsgroups with high local interest. Thus the timeout should be configurable on a per newsgroup basis.
Since NEWSCACHE has to fit into the current News system seamlessly, it can only rely on interfaces that are already used in existing news readers and servers. This compatibility requirement implies that the client-side interface must use NNRP, because this protocol is used by news clients for article retrieval.
On the server side either NNRP or NNTP must be used. NNTP has several disadvantages for this purpose, since it was designed for the transmission of a full news feed and requires maintenance work on the cache's news server to establish the news feed. Hence, we have decided to use NNRP for NEWSCACHE.
For the interaction among caches additional commands may be introduced (NNTP allows to define vendor-specific commands). Since these commands are only used between news caches they do not affect the compatibility with news clients and servers.
The replacement strategy has to be distinguished from the article expiration. Article expiration means that an article is removed from the news server after a given period of time. This can be detected using the newsgroup's low and high watermark. The replacement strategy, however, decides which article to remove from the cache to make place for the new article if no more space is available in the cache area.
Several replacement mechanisms are applicable:
Least Frequently Used replaces those articles with lowest access rates first. This strategy assumes that frequently accessed articles are more likely to be accessed again.
Least Recently Used replaces those articles with the oldest access time stamps first. The assumption is that articles which have not been accessed for a long period will not be accessed again.
Oldest Article First assumes that articles with older time stamps will be less probably accessed than newer ones. Additionally those articles would be expired by the news server earlier; consequently they would have to be removed from the cache anyway. In this context, oldest is meant relative to the expiration time of a specific newsgroup.
Biggest Article First assumes that the probability that one big article is referenced is lower than the probability that any of several smaller ones is accessed, which reuse the disk space of the big article. This strategy penalizes the binary newsgroups (e.g., the alt.binaries hierarchy).
At the moment we do not have enough evidence to judge which of the above strategies are the best. However, we assume that this may vary considerably according to user profiles and that a combination of the above strategies will prove to be optimal.
The current version of NEWSCACHE uses LRU on a per newsgroup basis.
Postings submitted to the cache server may be passed on to the news server directly. If the news server is not available, postings are queued for later submission.
Another possibility is to store postings on the cache in a way that makes them available to the user immediately, even though they have not been passed on to the news server. This strategy, however, requires the cache server to use its own article numbering, since an article number must be assigned to each article that is presented to the user. This implies that the cache server has to maintain a mapping between local article numbers and news server article numbers. Additionally the user cannot switch between different NEWSCACHES attached to the same news server because news clients usually use the article numbers to log articles read by the user. NEWSCACHE uses the first approach.
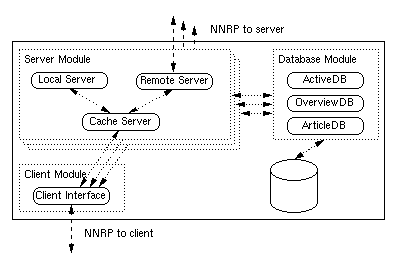
The architecture of NEWSCACHE is divided into several components as shown in Figure 5. The server module serves as the communication facility between the database module, which stores the news articles and related information and the client module, which handles the communication with the news clients.
The server module is also responsible for the interaction with news servers. The remote server component implements a news server for accessing the news database of other news servers. This component allows developers to implement news readers without knowing the details of NNRP, because it encapsulates all communication actions.
The local server component implements a news server with a local news database and can be used as a base for a fully featured news server.
The cache server component combines the local and remote server components and implements the cache functionality. It uses the remote server to retrieve news from other news servers and uses the local server to cache received information. All types of information--articles, overview database, and active database--are cached and maintained by this component.
The client interface handles the connections to news readers. When a request is received from a news reader, the client interface chooses a server module based on the name of the current newsgroup. The client interface also translates the client's request into the cache server component's programmatic interface. The cache server component then checks whether the request can be fulfilled by the local server component. If so, the local server passes the information back to the cache server, which returns it to the client interface. Otherwise, a request is sent to the remote server component which in turn submits it to the news server. As soon as the request is completed by the news server, the result is passed on to the appropriate database component and to the cache server component which returns it to the client interface. Finally, the client interface translates the result into NNRP data format.
Since the same news database is shared by all server components and all processes of NEWSCACHE running on one machine, the information requested from the news server is available to all other components and to all NEWSCACHE processes as soon as it is passed to the database by the remote server component.
As explained in [14] the news server of our university has been switched to the lightweight news server model. If a newsgroup is not available users can request it to be added to the news server. A WWW interface for such requests exists. By using a cache server this could be implemented transparently and would not require any interaction from the user. In the average our news server spools one tenth of the theoretically possible news feed.
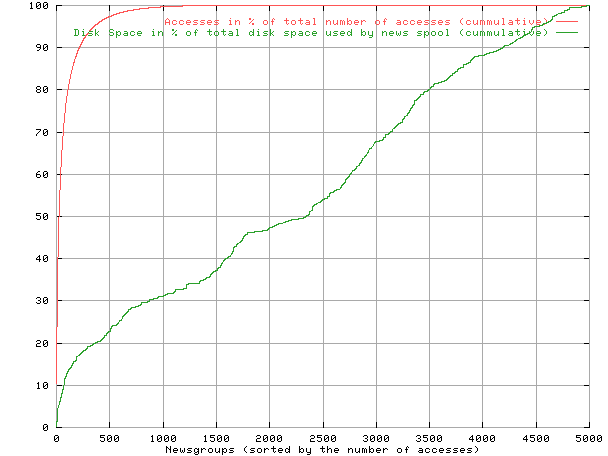
Figure 6 shows the percentage of accesses to the top n percent of the news groups (solid line) and the amount of disk space they use in percent of the size of the total news spool (dashed line). This shows that for instance, the 10% most frequently read newsgroups make up 97% of all the accesses but only 23% of the news spool. The values are taken from news.tuwien.ac.at which holds 60GB of article data and is accessed about 15000 times by 700 different hosts each day [15].
To evaluate the benefits of caching, we have setup NEWSCACHE with a cache area of 3GB disk space and our university's news server as its upstream news server. An analysis of NEWSCACHE's log files shows that even though the cache server was used by only 5% of the users (about 600 accesses by 60 different hosts each day), we got a hit rate of 25%. With more accesses to the cache we expect even higher hit rates, especially when people have to use the cache and cannot access the news server directly.
To ensure inter operability with existing News software, we have tested NEWSCACHE with different versions of INN [18], which is by far the most frequently used server software. Some users of NEWSCACHE reported problems with other news servers which have been fixed by now (e.g., AMU NEWS under VMS). Most of the problems with other news servers originate from not implementing RFC977 or the new NNTP draft [4] precisely.
The most popular news readers have been tested with NEWSCACHE, too. GNUS (Emacs) and TIN work without any problems. XRN works without problems but required some additional effort since it insists on optional features explained in [4]. Netscape's news reader works without any problems. Since it issues the GROUP command for every newsgroup to get a better estimation of the number of articles within the newsgroup, NEWSCACHE's active database had to be optimized to make this delay small.
Currently, an increasing number of sites are using NEWSCACHE and it is already included in the Debian Linux distribution [1].
Related work focuses on statistics to forecast Usenet growth, on managing the resulting load on news servers, and on improving the News infrastructure and NNTP.
How resource requirements of News are monitored at the Stanford Linear Accelerator Center is presented in [19]. The goal is to forecast News growth and derive plans for hardware changes in order to guarantee stable operation of the news server.
An administrative ad hoc solution for growing resource requirements of News is given in [5]. It is intended for a news server at a single site, does not attack general News infrastructure problems, and requires significant hardware investments. The idea is to have a dedicated server that manages the news feed and several other servers that can access the news spool read-only offering read access to clients. Thus reading load is distributed and the server being in charge of the news feed is freed from read accesses. Additionally, the news spool disk space is partitioned among all servers. Access to the complete news spool is provided by extensive use of NFS cross-mounts.
NNTPCACHE [3] takes a similar approach like NEWSCACHE. While NEWSCACHE uses a specialized hash table for storing the active database, NNTPCACHE uses UNIX dbm format. For performance reasons both systems store the overview database in memory mapped databases using proprietary formats. Features of NNTPCACHE not yet included in NEWSCACHE are: censoring of articles, and forwarding of unknown commands. On the other hand NEWSCACHE offers prefetching, off-line News reading, and UNIX inetd support which are not supported by NNTPCACHE. Since no papers on NNTPCACHE were available at the time of this writing, the above statements are based on NNTPCACHE's implementation and our tests with it.
A networking-level approach based on multicast to attack the article distribution problem is given in [17]. This approach has already been discussed in Section 4.3.
In this paper we have analyzed the current status of the News infrastructure and identified disk space consumption, enormous I/O load, and network bandwidth bottlenecks as its main problems.
We discussed several solution strategies like the lightweight server model, compressed article distribution, multicast, and a caching infrastructure. Additionally we presented an enhanced infrastructure using cache servers for future News distribution. This infrastructure fits seamlessly into the existing infrastructure without requiring modifications to existing software. As we explained, another advantage of this approach is that it does not impose new hardware requirements and that the administrative overhead is decreased.
It attacks the identified problems, supports flexible architectural usage patterns, is scalable, and can easily be adapted to future News standards. We believe that NEWSCACHE or components that offer similar properties will soon be added to the existing News infrastructure since its scalability problems will get worse due to the continuing growth of Usenet. Future work on NEWSCACHE will focus on improved storage models for News databases and management support.
A detailed description of the initial NEWSCACHE prototype is given in [10]. The NEWSCACHE software is available at http://www.infosys.tuwien.ac.at/NewsCache/.
We want to thank Michael Gschwind and Mehdi Jazayeri for their comments on draft versions.